Random variable
In mathematics, a random variable (or stochastic variable) is (in general) a measurable function that maps a probability space into a measurable space. Random variables mapping all possible outcomes of an event into the real numbers are frequently studied in elementary statistics and used in the sciences to make predictions based on data obtained from scientific experiments. In addition to scientific applications, random variables were developed for the analysis of games of chance and stochastic events. The utility of random variables comes from their ability to capture only the mathematical properties necessary to answer probabilistic questions.
While the above definition of a random variable requires a familiarity with measure theory to appreciate, the language and structure of random variables can be grasped at various levels of mathematical fluency through limiting the variables one considers. Beyond the introductory level, however, set theory and calculus are fundamental to their study. The concept of a random variable is closely linked to the term "random variate": a random variate is a particular outcome (value) of a random variable.
There are two types of random variables: discrete and continuous.[1] A discrete random variable maps events to values of a countable set (e.g., the integers), with each value in the range having probability greater than or equal to zero. A continuous random variable maps events to values of an uncountable set (e.g., the real numbers). In a continuous random variable, the probability of any specific value is zero, although the probability of an infinite set of values (such as an interval of non-zero length) may be positive. However, a random variable can be "mixed", having part of its probability spread out over an interval like a typical continuous variable, and part of it concentrated on particular values, like a discrete variable. This categorisation into types is directly equivalent to the categorisation of probability distributions.
A random variable has an associated probability distribution and frequently also a probability density function. Probability density functions are commonly used for continuous variables.
Contents |
Intuitive description
In the simplest case, a random variable maps events to real numbers. A random variable can be thought of as a function mapping the sample space of a random process to a set of numbers or quantifiable labels.
Examples
For a coin toss, the possible events are heads or tails. The possible outcomes for one fair coin toss can be described using the following random variable:
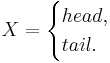
and if the coin is equally likely to land on either side then it has a probability mass function given by:
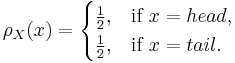
It is sometimes convenient to model this situation using a random variable which takes numbers as its values, rather than the values head and tail. This can be done by using the real random variable 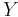 defined as follows:
defined as follows:
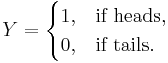
and if the coin is equally likely to land on either side then it has a probability mass function given by:
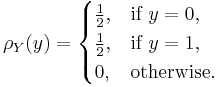
A random variable can also be used to describe the process of rolling a fair die and the possible outcomes. The most obvious representation is to take the set {1, 2, 3, 4, 5, 6} as the sample space, defining the random variable X as the number rolled. In this case,

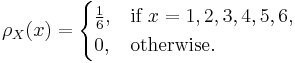
An example of a continuous random variable would be one based on a spinner that can choose a horizontal direction. Then the values taken by the random variable are directions. We could represent these directions by North West, East South East, etc. However, it is commonly more convenient to map the sample space to a random variable which takes values which are real numbers. This can be done, for example, by mapping a direction to a bearing in degrees clockwise from North. The random variable then takes values which are real numbers from the interval [0, 360), with all parts of the range being "equally likely". In this case, X = the angle spun. Any real number has probability zero of being selected, but a positive probability can be assigned to any range of values. For example, the probability of choosing a number in [0, 180] is ½. Instead of speaking of a probability mass function, we say that the probability density of X is 1/360. The probability of a subset of [0, 360) can be calculated by multiplying the measure of the set by 1/360. In general, the probability of a set for a given continuous random variable can be calculated by integrating the density over the given set.
An example of a random variable of mixed type would be based on an experiment where a coin is flipped and the spinner is spun only if the result of the coin toss is heads. If the result is tails, X = −1; otherwise X = the value of the spinner as in the preceding example. There is a probability of ½ that this random variable will have the value −1. Other ranges of values would have half the probability of the last example.
Non-real-valued form
Very commonly a random variable takes values which are numbers. This is by no means always so; one can consider random variables of any type. This often includes vector-valued random variables or complex-valued random variables, but in general can include arbitrary types such as sequences, sets, shapes, manifolds, matrices, and functions.
Formal definition
Let (Ω, ℱ, P) be a probability space, and (E, ℰ) a measurable space. Then an (E, ℰ)-valued random variable is a function X: Ω→E, which is (ℱ, ℰ)-measurable. That is, such function that for every subset B ∈ ℰ, its preimage lies in ℱ: X −1(B) ∈ ℱ, where X −1(B) = {ω: X(ω) ∈ B}.[2]
When E is a topological space, then the most common choice for the σ-algebra ℰ is to take it equal to the Borel σ-algebra ℬ(E), which is the σ-algebra generated by the collection of all open sets in E. In such case the (E, ℰ)-valued random variable is called the E-valued random variable. Moreover, when space E is the real line ℝ, then such real-valued random variable is called simply the random variable.
The meaning of this definition is following: suppose (Ω, ℱ, P) is the underlying probability space, whereas we want to consider a probability space based on the space E with σ-algebra ℰ. In order to turn the pair (E, ℰ) into a probability space, we need to equip it with some probability function, call it Q. This function would have to assign the probability to each set B in ℰ. If X is some function from Ω to E, then it is natural to postulate that the probability of B must be the same as the probability of its preimage in Ω: Q(B) = P(X −1(B)). In order for this formula to be meaningful, X −1(B) must lie in ℱ, since the probability function P is defined only on ℱ. And this is exactly what the definition of the random variable requires: that X −1(B) ∈ ℱ for every B ∈ ℰ.
Real-valued random variables
In this case the observation space is the real numbers with a suitable measure. Recall, 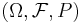 is the probability space. For real observation space, the function
is the probability space. For real observation space, the function 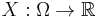 is a real-valued random variable if
is a real-valued random variable if
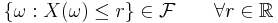
This definition is a special case of the above because ![\{(-\infty, r]: r \in \R\}](/I/7e978ff4357b04dc715271f1cc743566.png) generates the Borel sigma-algebra on the real numbers, and it is enough to check measurability on a generating set. (Here we are using the fact that
generates the Borel sigma-algebra on the real numbers, and it is enough to check measurability on a generating set. (Here we are using the fact that ![\{ \omega�: X(\omega) \le r \} = X^{-1}((-\infty, r])](/I/4b71a32b862a640cf96aa20333258f40.png) .)
.)
Distribution functions of random variables
Associating a cumulative distribution function (CDF) with a random variable is a generalization of assigning a value to a variable. If the CDF is a (right continuous) Heaviside step function then the variable takes on the value at the jump with probability 1. In general, the CDF specifies the probability that the variable takes on particular values.
If a random variable  defined on the probability space is given, we can ask questions like "How likely is it that the value of
defined on the probability space is given, we can ask questions like "How likely is it that the value of 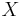 is bigger than 2?". This is the same as the probability of the event
is bigger than 2?". This is the same as the probability of the event  which is often written as
which is often written as 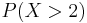 for short, and easily obtained since
for short, and easily obtained since 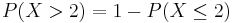
Recording all these probabilities of output ranges of a real-valued random variable X yields the probability distribution of X. The probability distribution "forgets" about the particular probability space used to define X and only records the probabilities of various values of X. Such a probability distribution can always be captured by its cumulative distribution function
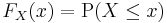
and sometimes also using a probability density function. In measure-theoretic terms, we use the random variable X to "push-forward" the measure P on Ω to a measure dF on R. The underlying probability space Ω is a technical device used to guarantee the existence of random variables, and sometimes to construct them. In practice, one often disposes of the space Ω altogether and just puts a measure on R that assigns measure 1 to the whole real line, i.e., one works with probability distributions instead of random variables.
Moments
The probability distribution of a random variable is often characterised by a small number of parameters, which also have a practical interpretation. For example, it is often enough to know what its "average value" is. This is captured by the mathematical concept of expected value of a random variable, denoted E[X], and also called the first moment. In general, E[f(X)] is not equal to f(E[X]). Once the "average value" is known, one could then ask how far from this average value the values of X typically are, a question that is answered by the variance and standard deviation of a random variable.
Mathematically, this is known as the (generalised) problem of moments: for a given class of random variables X, find a collection {fi} of functions such that the expectation values E[fi(X)] fully characterise the distribution of the random variable X.
Functions of random variables
If we have a random variable 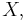 on
on 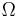 and a Borel measurable function
and a Borel measurable function 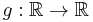 , then
, then 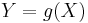 will also be a random variable on , since the composition of measurable functions is also measurable. (However, this is not true if
will also be a random variable on , since the composition of measurable functions is also measurable. (However, this is not true if 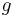 is Lebesgue measurable.) The same procedure that allowed one to go from a probability space
is Lebesgue measurable.) The same procedure that allowed one to go from a probability space 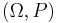 to
to 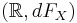 can be used to obtain the distribution of
can be used to obtain the distribution of 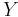 . The cumulative distribution function of is
. The cumulative distribution function of is
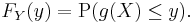
If function g is invertible, i.e. g-1 exists, and increasing, then the previous relation can be extended to obtain
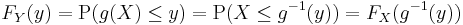
and, again with the same hypotheses of invertibility of g, assuming also differentiability, we can find the relation between the probability density functions by differentiating both sides with respect to y, in order to obtain
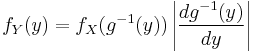 .
.
If there is no invertibility of g but each y admits at most a countable number of roots (i.e. a finite, or countably infinite, number of xi such that y = g(xi)) then the previous relation between the probability density functions can be generalized with
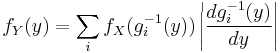
where xi = gi-1(y). The formulas for densities do not demand g to be increasing.
Example 1
Let X be a real-valued, continuous random variable and let Y = X2.
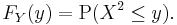
If y < 0, then P(X2 ≤ y) = 0, so

If y ≥ 0, then
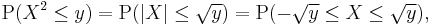
so
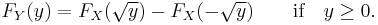
Example 2
Suppose 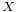 is a random variable with a cumulative distribution
is a random variable with a cumulative distribution
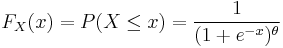
where 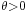 is a fixed parameter. Consider the random variable
is a fixed parameter. Consider the random variable 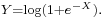 Then,
Then,
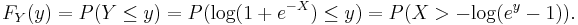
The last expression can be calculated in terms of the cumulative distribution of 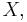 so
so
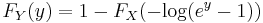
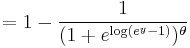
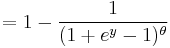
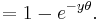
Equivalence of random variables
There are several different senses in which random variables can be considered to be equivalent. Two random variables can be equal, equal almost surely, equal in mean, or equal in distribution.
In increasing order of strength, the precise definition of these notions of equivalence is given below.
Equality in distribution
If the sample space is a subset of the real line a possible definition is that random variables X and Y are equal in distribution if they have the same distribution functions:
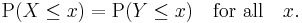
Two random variables having equal moment generating functions have the same distribution. This provides, for example, a useful method of checking equality of certain functions of i.i.d. random variables. However, the moment generating function exists only for distributions that are good enough.
Almost sure equality
Two random variables X and Y are equal almost surely if, and only if, the probability that they are different is zero:
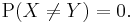
For all practical purposes in probability theory, this notion of equivalence is as strong as actual equality. It is associated to the following distance:
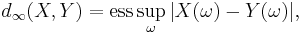
where "ess sup" represents the essential supremum in the sense of measure theory.
Equality
Finally, the two random variables X and Y are equal if they are equal as functions on their probability space, that is,

Convergence
Much of mathematical statistics consists in proving convergence results for certain sequences of random variables; see for instance the law of large numbers and the central limit theorem.
There are various senses in which a sequence (Xn) of random variables can converge to a random variable X. These are explained in the article on convergence of random variables.
See also
- Observable variable
- Probability distribution
- Algebra of random variables
- Multivariate random variable
- Event (probability theory)
- Randomness
- Random element
- Random vector
- Random function
- Random measure
- Stochastic process
References
- ↑ Rice, John (1999). Mathematical Statistics and Data Analysis. Duxbury Press. ISBN 0534209343.
- ↑ Fristedt & Gray (1996, page 11)
Literature
- Fristedt, Bert; Gray, Lawrence (1996). A modern approach to probability theory. Boston: Birkhäuser. ISBN 3-7643-3807-5.
- Kallenberg, O., Random Measures, 4th edition. Academic Press, New York, London; Akademie-Verlag, Berlin (1986). MR0854102 ISBN 0-12-394960-2
- Kallenberg, O., Foundations of Modern Probability, 2nd edition. Springer-Verlag, New York, Berlin, Heidelberg (2001). ISBN 0-387-95313-2
- Papoulis, Athanasios 1965 Probability, Random Variables, and Stochastic Processes. McGraw–Hill Kogakusha, Tokyo, 9th edition, ISBN 0-07-119981-0.
This article incorporates material from Random variable on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||